Category: Others
-

10 Claude Code Tips from the Creator Boris Cherny | February 2026
Learn 10 expert Claude Code tips from creator Boris Cherny and the Anthropic team. Master git worktrees, plan mode, CLAUDE.md, custom skills, MCP bug fixing, subagents, and more from the viral thread with 8.5 million views.
-

OpenClaw Auto-Recovery & Config Fix Guide | 2026
Master OpenClaw auto-recovery with this comprehensive guide covering config corruption fixes, backup restoration cascade, gateway health monitoring with 5 health checks, and intelligent error auto-remediation for 24/7 AI assistant uptime.
-

OpenClaw Troubleshooting Guide: 7 Common Errors and How to Fix Them | February 2026
Fix OpenClaw errors fast: Brave API rate limits, SearXNG Docker issues, LLM command hallucinations, and agent workflow issues with step-by-step solutions.
-

Generate Images using AI – Stable Diffusion
Using stable diffusion on Mac M1 system
-
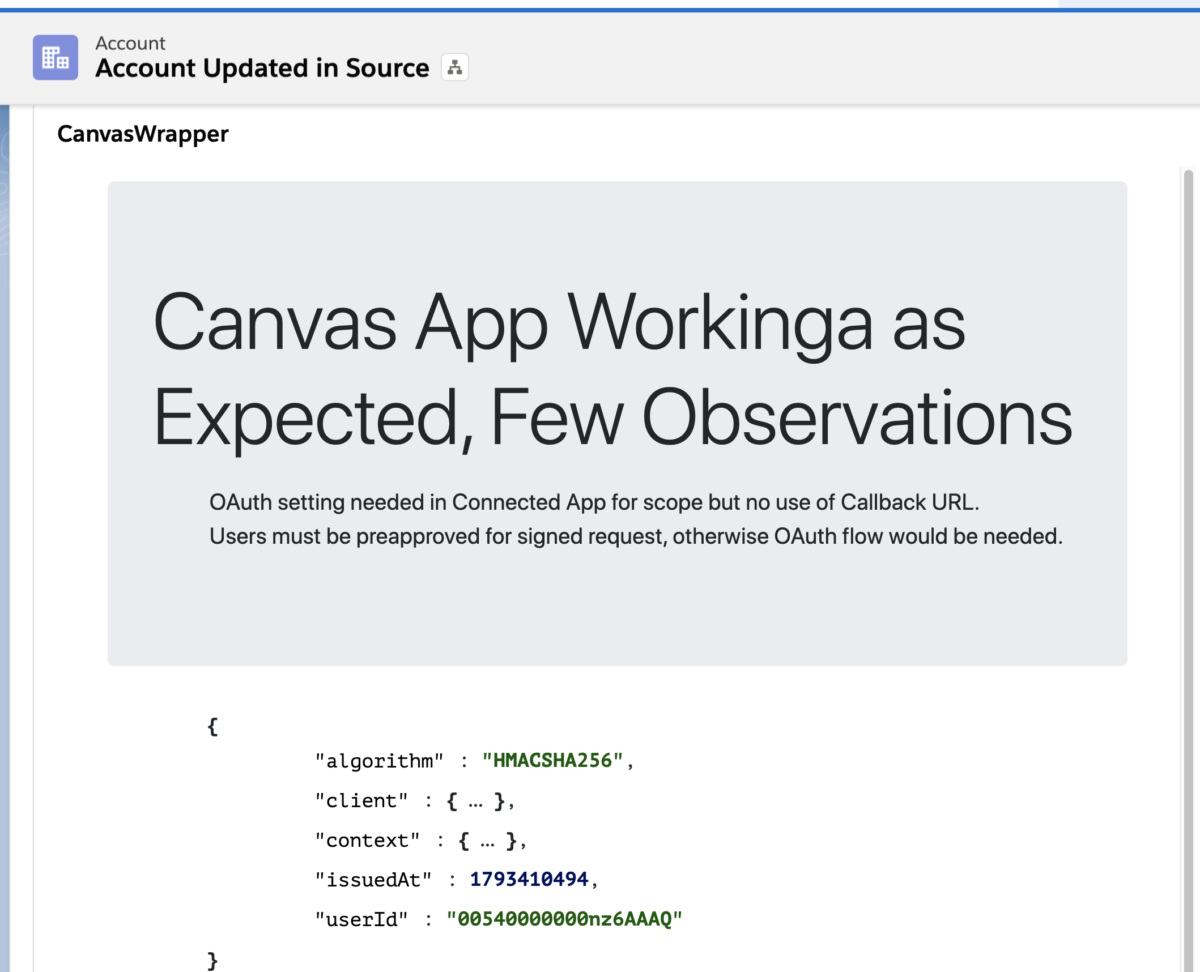
Salesforce Integration with Nodejs based applications using Canvas
How to use Canvas Signed Request Authentication with web based applications like Nodejs & how to use Canvas LifeCycle Handler Class
-
Shell Script – Read all file names in Git Pull Request
Shell script to read all files part of Pull Request & iterate through them
-
Frequently Used Git Commands
Most frequently used Git commands by developers
-
What is Micro Services
I have read many posts and watched video to understand Microservices precisely however I found Martin Fowler’s explanation about Microservices most helpful. This blog post is just the recap & summary of what I understood about Microservices Architecture. Characteristics of Microservices Build services in form of Components Components can be independently replaceable and upgradable Components…
-
Definition of Frequently Used Database Architecture Related Terms
Definitions of Data warehouse, Data lake, Data Mart, Operational Data Store
-
Housie / Tambola / Bingo Game Number Generator
Online free Housie / Tambola / Bingo Game. Simple to use and play with Bingo Number descriptions